CoCoSpot: Recognizing Botnet C2 Channels Using Traffic Analysis
A defining characteristic of a bot is its ability to be remote-controlled by way of command and control (C2). Typically, a bot receives commands from its master, performs tasks and reports back on the execution results. All communication between a C2 server and a bot is performed using a specific C2 protocol over a certain C2 channel. Consequently, in order to instruct and control their bots, bot masters ‐ knowingly or not ‐ have to define and use a certain command and control protocol.
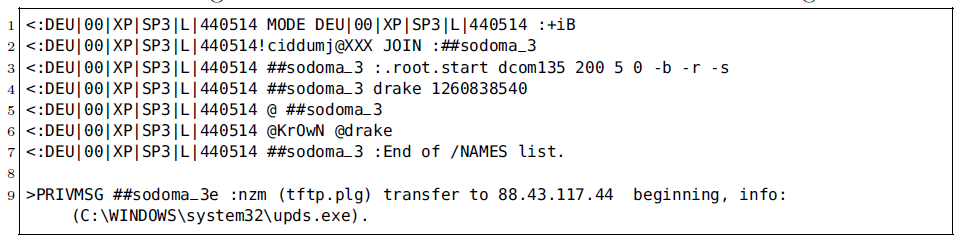
Historically, bots used cleartext C2 protocols, such as plaintext messages transmitted using IRC or HTTP, as shown in the Rbot C2 example above. However, a C2 channel relying on a plaintext protocol can easily be detected. Methods such as payload byte signatures or heuristics on common C2 message elements such as IRC nicknames are examples for such detection techniques. To evade payload-based detection, botnets have evolved and often employ C2 protocols with obfuscated or encrypted messages as is the case with Waledac, Zeus, Hlux, TDSS/Alureon, Palevo, Renos, Virut and Feederbot, to name but a few. In fact, pretty much all recent botnets employ some kind of encryption in their C2 protocol. The following two images show an encrypted Virut C2 message and its decrypted plaintext. This reveals that the underlying carrier protocol is still IRC, or IRC-like. The encryption is basically a four-byte XOR with a random bot-chosen key.


The change towards encrypted or obfuscated C2 messages effectively prevents detection approaches that rely on plaintext C2 message contents. Lately, we take a different approach to recognize C2 channels of botnets and fingerprint botnet C2 channels based on traffic analysis properties. The rationale behind our methodology is that for a variety of botnets, characteristics of their C2 protocol manifest in the C2 communication behavior. For this reason, our recognition approach is solely based on traffic analysis.
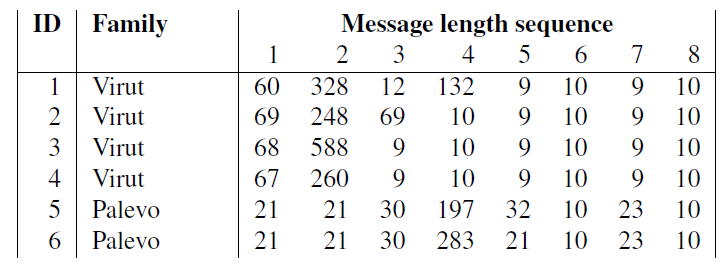
As an example, consider a C2 protocol that defines a specific handshake – e.g., for mutual authentication – to be performed in the beginning of each C2 connection. Each request and response exchanged during this handshake procedure conforms to a predefined structure and length, which in turn leads to a characteristic sequence of message lengths. In fact, we found that in the context of botnet C2, the sequence of message lengths is a well-working example for traffic analysis features. The following figure shows the sequence of the first 8 messages in four Virut C2 flows and two Palevo/Rimecud/Pilleuz C2 flows. Whereas Virut exhibits similar message lengths for the first message (in the range 60-69) and a typical sequence of message lengths at positions five to eight, for Palevo, the first three message lengths provide a characteristic fingerprint.
Leveraging statistical protocol analysis and hierarchical clustering analysis, we develop CoCoSpot, a method to group similar botnet C2 channels and derive fingerprints of C2 channels based on the message length sequence, the underlying carrier protocol and encoding properties. The huge benefit of our approach is to be independent from payload byte signatures which enables the detection of C2 protocols with obfuscated and encrypted message contents. In addition, our C2 flow fingerprints complement existing detection approaches while allowing for finer granularity compared to IP address or domain blacklists. As a side-effect, our C2 flow clustering can be used to discover relationships between malware families, based on the distance of their C2 protocols. Experiments with more than 87,000 C2 flows as well as over 1.2 million Non-C2 flows have shown that our classification method can reliably detect C2 flows for a variety of recent botnets with very few false positives.
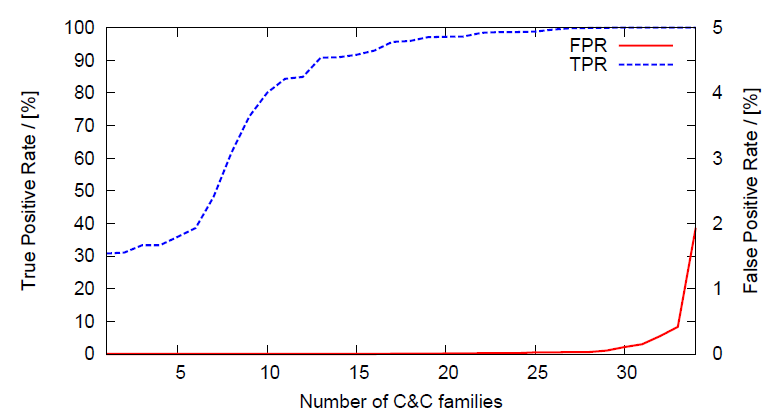
The figure above shows the results of the CoCoSpot classification as a cumulative distribution function for all families that were included in both, true positive and false positive analysis. Note that the true positive rate values are given on the left y-axis, the false positive rate values on the right y-axis. More than half of all families have a true positive rate of over 95.6%. A small fraction of seven C2 families had true positives rates lower than 50%, which was caused by too specific cluster centroids. In most of these cases, we had too little training data to learn representative message length variations of a particular active C2 protocol, which could be improved by adding more training data for this family. For 88% of the families, the false positive rate is below 0.1%, and 23 cluster families do not exhibit any false positive at all. For the few families that cause false positives, we observed that the corresponding cluster centroids have high variation coefficients on many message length positions, effectively rendering the centroids being too generic and possibly matching random flow patterns.
See here for our CoCoSpot paper.